|
APBRmetrics
The statistical revolution will not be televised.
|
| View previous topic :: View next topic |
| Author |
Message |
dsparks
Joined: 22 Feb 2008
Posts: 61
|
 Posted: Mon Feb 25, 2008 6:59 am Post subject: NBA playing style similarity network diagram Posted: Mon Feb 25, 2008 6:59 am Post subject: NBA playing style similarity network diagram |
 |
|
Hello all,
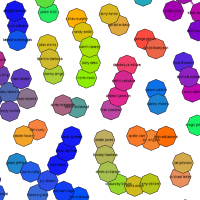
I am wondering if I could have some feedback on my work on the network diagrams here: http://arbitrarian.wordpress.com/2008/02/22/nba-similarity-networks/
There are links to methodological details within that post. I am under the impression that others have used factor analysis to isolate statistics on which to do matching, but I was attempting to go as "objective" as possible. I would sincerely appreciate any commentary you may have, including:
a) Do the comparisons seem generally valid?
b) Are there comparisons that surprise you, but on reflection, make sense?
c) Are there comparisons that are so counterintuitive that they couldn't possibly be valid?
Thank you for your time.
David
http://arbitrarian.wordpress.com |
|
| Back to top |
|
 |
Mike G
Joined: 14 Jan 2005
Posts: 3615
Location: Hendersonville, NC
|
| Posted: Mon Feb 25, 2008 9:01 am Post subject: |
|
|
Fascinating, to say the least. At first glance, it looks 3-D. Of course, there are even more D's than that.
Mostly I'm seeing intuitive matches. Browsing the perimeter, we see rebounders who don't score, scorer-rebounders who don't pass, etc.
Near Larry Bird, I find Kevin Garnett and Julius Erving. OK. But there's Tayshaun Prince -- other than height, almost the opposite player. Statistically-similar Grant Hill is clear over on the far side of the field.
Following this link:
http://arbitrarian.wordpress.com/2008/02/18/objective-statistical-player-matching/
... you've described a formula:
# Generate set of names and all boxscore counting statistics.
# For each player in the set, generate a set of ratios for each boxscore stat over every other.
# Percentile these, so that ratios with typically low values (e.g. pts/fga) are not outweighed by those with typically high values (e.g. min/bk).
# Find the Euclidean distance between each pair of players in n^2-space, by finding the square root of the sum of squared differences between each player’s ratios
So, if Prince gets 2.4 times as many points as rebounds, he is considered similar to Bird (in this ratio); even if one player is a 24-10 producer, while the other is a 12-5 guy. Am I understanding that correctly?
I also do similarities using boxscore stats and Euclidean distance. I just use per-minute rates, pace-standardized. A 24-10 player (per 36) looks more similar to a 25-8 player than to a 12-5 player. In a game, they're more interchangeable.
_________________
`
36% of all statistics are wrong |
|
| Back to top |
|
|
Ed Küpfer
Joined: 30 Dec 2004
Posts: 787
Location: Toronto
|
| Posted: Mon Feb 25, 2008 9:33 am Post subject: |
|
|
Thank you, I've been waiting for someone to get on this. Miscellaneous observations:
- In one of your posts, you wrote
| dsparks wrote: | | ... trying to come up with a way to estimate players’ positions from the data. I did come up with a pretty novel method, which works about 70% of the time... |
Can you describe more precisely what the 70% means?
- From experience, I know the "percentalization" method of normalisation works fine. However, I am concerned about the choice of inputs, which is something I had trouble with. For example, you have
| dsparks wrote: | | “Big” = (tr+bk)/(fga+tr+as+st+bk) |
If you add turnovers to that, would it change the distances significantly? I would have more confidence if you validated by substituting (or differently weighting) other stats. (Wait, now I read this, which seems to account for it. I'm a little confused now as to what the Big formula is for.)
- I love the output graph, but the names are hard to read. Can you make the font a different colour than the nodes?
_________________
ed |
|
| Back to top |
|
|
dsparks
Joined: 22 Feb 2008
Posts: 61
|
| Posted: Mon Feb 25, 2008 10:58 am Post subject: Thanks for responses |
|
|
First of all, thanks a lot for responding. This is just a free-time hobby for me, and while I think it's interesting, I don't really have the level of basketball (or statistical) knowledge I would like to have, so I appreciate this community's feedback and interest.
| Quote: |
So, if Prince gets 2.4 times as many points as rebounds, he is considered similar to Bird (in this ratio); even if one player is a 24-10 producer, while the other is a 12-5 guy. Am I understanding that correctly? |
Using the ratios method I described, yes, this is correct.
| Quote: |
I also do similarities using boxscore stats and Euclidean distance. I just use per-minute rates, pace-standardized. A 24-10 player (per 36) looks more similar to a 25-8 player than to a 12-5 player. In a game, they're more interchangeable. |
This is a good idea. I went ahead and made a network diagram using (un-pace-adjusted) per-minute statistics, and posted that here: http://arbitrarian.wordpress.com/2008/02/25/nba-player-similarities-matrix-revisited/
The matches look as good or better than using the ratios methodology, I would say, especially if you're looking for "substitutability" comparisons. Here, your 24/10 guy looks more like a 25/8 guy than a 12/5 guy. Bird is still most closely matched with Garnett and Webber (which I love, because I think all-around guys like that are just awesome--Bird is one of Lebron's closest matches, too.), and Prince is way far away. The only downside is that you lose the "fun counterintuitives" like Mullin and Jordan's proximity. Also, I think there is something to be said for the idea that, using the ratios method, you're getting two players who have a similar probability distribution over what they will do when given a possession, regardless of per-minute efficiency. However, I'm glad you suggested the per-minute method--it looks good, and I love an excuse to make another diagram.
| Quote: | In one of your posts, you wrote
dsparks wrote:
... trying to come up with a way to estimate players’ positions from the data. I did come up with a pretty novel method, which works about 70% of the time...
Can you describe more precisely what the 70% means? |
This quote refers to something that's not published on the blog, but can be seen here: http://www.duke.edu/~dbs9/envisioning/files/proximity%20p0sitions.txt
The p0s column is an estimated position, based on "ideal types". I don't want to get all into the details now, but the methodology is similar to the ratio matching method. Mostly, I was just messing around, but the results were interesting enough to at least publish in part. What I mean by 70% is that in the small sample I link to in the .txt above, I believe I have a 70% accuracy rate in correctly identifying each players' dominant position. Again, I haven't fully vetted this, but if there's enough interest, I'd be willing to investigate it futher.
| Quote: | dsparks wrote:
“Big” = (tr+bk)/(fga+tr+as+st+bk)
If you add turnovers to that, would it change the distances significantly? I would have more confidence if you validated by substituting (or differently weighting) other stats. (Wait, now I read this, which seems to account for it. I'm a little confused now as to what the Big formula is for.) |
The Big, Shooter, and Guard characterizations, as well as the color scheme in general, are just that: used for the color scheme and not the analysis. Raw box score stats are used to generate the ratios and proximities. However, I think that the RGB scheme does a pretty good job of highlighting playing style, broadly construed, and I think the aesthetic is extremely compelling. I would be willing to listen to other suggestions for color-classification, although I'm pretty smitten with this one, especially given that I'm not basing any real conclusions on it.
| Quote: | | I love the output graph, but the names are hard to read. Can you make the font a different colour than the nodes? |
If you go to my update post here: http://arbitrarian.wordpress.com/2008/02/25/nba-player-similarities-matrix-revisited/, at the bottom, I've made a high-contrast version just for you. |
|
| Back to top |
|
|
Mountain
Joined: 13 Mar 2007
Posts: 1527
|
| Posted: Mon Feb 25, 2008 1:41 pm Post subject: |
|
|
| Glad you made it here. I'd been by your site a few times in the past and noted it and got back to see the recent work and almost posted and linked to it but haven't blown up the charts to where I can read them and all the supporting documents yet. I may comment later. |
|
| Back to top |
|
|
dsparks
Joined: 22 Feb 2008
Posts: 61
|
|
| Back to top |
|
|
Harold Almonte
Joined: 04 Aug 2006
Posts: 616
|
| Posted: Mon Feb 25, 2008 8:03 pm Post subject: |
|
|
| I think you need to put some carthessian order to that dish. |
|
| Back to top |
|
|
Mountain
Joined: 13 Mar 2007
Posts: 1527
|
| Posted: Tue Feb 26, 2008 12:47 am Post subject: |
|
|
There are some significant threads showcasing some of Ed's work with similaities studies, cluster or factor analysis and what have you in back pages of the forum that he can point you to or you can find by searching his posts.
But for what it may be worth in response to this statement in your most recent article:
"I would be very interested in collectively coming up with a sort of “baller’s taxonomy,” wherein we try and identify the different clusters using some more subjective terms. I think we could come up with a better vocabulary to describe players and define playing styles. If you have any ideas, please put them in the comments"
this thread had my earlier attempt at a list of player types / labels and some discussion with Ed and others that you might find interesting or of use.
http://tinyurl.com/2grwce |
|
| Back to top |
|
|
findingneema
Joined: 25 Feb 2008
Posts: 34
Location: Atlanta, GA
|
| Posted: Fri Feb 29, 2008 2:42 pm Post subject: |
|
|
So I decided to try a neural net clustering of these distances, using the correlations between each of the players. It seems like a 4x3 model fits pretty well. Some highlights:
12 nodes, having ([13 67 102] [6 24 12] [44 33 20] [92 59 28]) members
nodes (1,2) and (1,3) are the most similar, comprising 169 players
nodes (4,1) and (4,2) are the next most similar, comprising 151 players
2 broad classes are formed, a big men class, comprising nodes (1,1),(1,2),(1,3),(2,2),(2,3) and the not big men being the remainder
node (1,1) is the node furthest from any other, with no big name players (some members include Derrick McKey, Tom Gugliotta, and George Lynch)
NBA Top50 players (many of them are not in this data set):
(1,2)
Dave Cowens, Wes Unseld
(1,3)
Kareem Abdul-Jabbar, Patrick Ewing, Elvin Hayes, Moses Malone, Kevin McHale, Hakeem Olajuwon, Shaquille O'Neal, Robert Parish, David Robinson
(2,3)
Charles Barkley, Julius Erving, Karl Malone
(3,1)
Scottie Pippen
(3,2)
Larry Bird, Clyde Drexler, James Worthy
(3,3)
George Gervin, Michael Jordan
(4,2)
Tiny Archibald, Magic Johnson, John Stockton, Isiah Thomas |
|
| Back to top |
|
|
dsparks
Joined: 22 Feb 2008
Posts: 61
|
| Posted: Fri Feb 29, 2008 3:01 pm Post subject: I'm glad to see others have worked on this, too |
|
|
Harold: When I read your post, I didn't know what Cartesian order was, but then I looked it up, and I think you're right, except I don't know how to apply it to my plots.
Mountain: The thread you reference is a good read. I think it's interesting how there are so many approaches one could take to a classification system. I am, personally, a little reluctant to identify classes first, and then put players into them. This board is great because it seems like there are so many smart people with so many talents and ideas, just waiting to take a crack at any problem.
findingneema: Neural net clustering is a cool idea, albeit yet another subject I know little of. I would love to see a .csv of your output, if you're willing to share. I also seem to get a distinction between big men and ~big men in my analysis. I wonder if this is the "primary" fundamental axis of difference among players, or if this finding is just a function of our methods or the available statistics. For example, would we instead expect the "primary" axis to be defensive-leaning vs. offensive-leaning? Or scoring-minded vs. other-things-minded? This is all interesting stuff to me.
_________________
David
http://arbitrarian.wordpress.com |
|
| Back to top |
|
|
Ed Küpfer
Joined: 30 Dec 2004
Posts: 787
Location: Toronto
|
| Posted: Fri Feb 29, 2008 3:25 pm Post subject: |
|
|
I'm so happy to see some other folks try their hand at this, especially folks who (unlike me) know what they're doing.
I am concerned about validation. When I do classification, I usually run it at the player-season level -- I can then check each player-season's class against adjacent seasons. dsparks, I may have missed the post where you described your dataset -- are those career numbers for each player, or a particular season?
Also, your concern about a priori classes is relavant. However, from my perspective, I know certain classes of players exist -- these classes may be subjective to some degree, but there is wide concensus on the types. For example, the low-usage rebounding big defender is "out there" in some real sense. My primary interest is in a) seeing if these a priori classes "exist" as statistical classes (answer so far: some do, some don't), and b) seeing how well we can classify these players into homogenous groups (answer: some well, some not so well).
_________________
ed |
|
| Back to top |
|
|
dsparks
Joined: 22 Feb 2008
Posts: 61
|
| Posted: Fri Feb 29, 2008 3:34 pm Post subject: |
|
|
Ed: Your validation concern is a good one. The statistics I'm using are for the players' careers (actually, it's even narrower than that: the part of each player's career that falls between 1979-80 and 2006-07, which cuts a lot of careers short, like Kareem, for example--so this is not an ideal dataset. I offer a somewhat lame reason for my selection of these years here: http://arbitrarian.wordpress.com/2007/08/08/my-dataset/). If I have time, sometime in the near future, I may rerun one of the plots using the best single-seasons over this span, to see if we get Jordan matching Jordan, etc. I think this would be a good test of methodological validity, and also very interesting in itself.
I really like your idea of attempting to statistically locate these groups you (and all of us) know actually exist. I think another interesting step would be to classify teams based on their assortment of player types, or to identify collections of player types that work well together. Like, for example, is having a "star guard" a "star big" and a bunch of "glue guys" a recipe for success? Does pairing a scoring SG with a defensive PG lead to better outcomes? Etc, etc. Keep up the good work, and keep me posted on what you come up with.
_________________
David
http://arbitrarian.wordpress.com |
|
| Back to top |
|
|
findingneema
Joined: 25 Feb 2008
Posts: 34
Location: Atlanta, GA
|
| Posted: Fri Feb 29, 2008 3:40 pm Post subject: |
|
|
Some attempts at class descriptions:
(1,1) - Some not-so-notable forwards who tended to score about 10ppg (see above for examples)
(1,2) - PF and C who tend not to be big scorers, but do get boards (e.g. Marcus Camby, Vlade Divac, Chris Kaman, Horace Grant, Dennis Rodman, Ben Wallace)
(1,3) - PF and C who put the ball in the basket (e.g. the above Top50 players,
Elton Brand, Carlos Boozer, Yao Ming, Dwight Howard, Shawn Kemp, Ralph Sampson, Tim Duncan)
(2,1) - really small group, similar to node (3,1), G-F types with about 12 ppg and 4 rbg, (e.g. Blue Edwards, Bonzi Wells, Rodney Rogers)
(2,2) - forwards who score mostly from the wing, (e.g. Josh Howard, Sam Perkins, Luol Deng, Rasheed Wallace, Lamar Odom, Shawn Marion)
(2,3) - PF known for scoring, transitional node between (1.3) and (3,3), (e.g Karl Malone (though he's almost as close to (1,3), Charles Barkley, Dr. J, Tom Chambers)
(3,1) - wing F, not as good rebounders as (2,2), many known for 3pt shooting and/or defense, (e.g. Dan Majerle, Toni Kukoc, Mike Miller, Kyle Korver, Bruce Bowen, Scottie Pippen, Tayshaun Prince)
(3,2) - wing G/F, who shoot and score, (e.g. Chris Mullin, Vince Carter, Ron Artest, Rashard Lewis, Kobe Bryant, Ray Allen, Tracy McGrady, Paul Pierce, LeBron James, Michael Redd)
(3,3) - transitional group between (2,3) and (4,3), wing scorers, often pretty complete players, (e.g. Michael Jordan, Carmelo Anthony, Richard Jefferson, Dominique Wilkins, Adrian Dantley)
(4,1) - almost all PG, (e.g. Danny Ainge, Gary Payton, Jason Terry, Deron Williams, Derek Fisher, Tim Hardaway, Baron Davis, Joe Johnson, Jason Kidd)
(4,2) - PG who can score and SG mostly, (e.g. Monta Ellis, Isiah Thomas, John Stockton, Mark Price, Joe Dumars, Chris Paul, Chauncy Billups, Manu Ginobili, Gilbert Arenas, Allen Iverson, Reggie Miller, Magic Johnson)
(4,3) - SG, not generally 3pt shooters, (e.g. Richard Hamilton, Dwyane Wade, Calvin Murphy, Reggie Theus)
Last edited by findingneema on Fri Feb 29, 2008 3:47 pm; edited 1 time in total |
|
| Back to top |
|
|
findingneema
Joined: 25 Feb 2008
Posts: 34
Location: Atlanta, GA
|
| Posted: Fri Feb 29, 2008 3:45 pm Post subject: |
|
|
| Ed Küpfer wrote: | | I'm so happy to see some other folks try their hand at this, especially folks who (unlike me) know what they're doing. |
Thanks 
| Quote: | | Also, your concern about a priori classes is relavant. However, from my perspective, I know certain classes of players exist -- these classes may be subjective to some degree, but there is wide concensus on the types. For example, the low-usage rebounding big defender is "out there" in some real sense. My primary interest is in a) seeing if these a priori classes "exist" as statistical classes (answer so far: some do, some don't), and b) seeing how well we can classify these players into homogenous groups (answer: some well, some not so well). |
That class most definitely does exist, node (1,2) in my analysis. In fact, the players who score less and board and D-up more, like Ben Wallace, Dennis Rodman, and Marcus Camby, are the most prototypical members of the class (i.e. they are closest to the node center and furthest from (1,3), which has scoring big men). |
|
| Back to top |
|
|
findingneema
Joined: 25 Feb 2008
Posts: 34
Location: Atlanta, GA
|
| Posted: Fri Feb 29, 2008 3:54 pm Post subject: Re: I'm glad to see others have worked on this, too |
|
|
| dsparks wrote: | | findingneema: Neural net clustering is a cool idea, albeit yet another subject I know little of. I would love to see a .csv of your output, if you're willing to share. I also seem to get a distinction between big men and ~big men in my analysis. I wonder if this is the "primary" fundamental axis of difference among players, or if this finding is just a function of our methods or the available statistics. For example, would we instead expect the "primary" axis to be defensive-leaning vs. offensive-leaning? Or scoring-minded vs. other-things-minded? This is all interesting stuff to me. |
Working on it (the .csv). I would definitely argue the primary separation is big men vs not big men. Rebounds, blocks, and 3pt shooting, and to a lesser extent assists, are big separators that will overwhelm the differences between scorers and non-scorers. So what I see is that scoring tends to break up blocks of big vs not big. I need to go back and read all your posts and get a better feel for your algorithm to calculate the distances, so I can better understand what's going on. But I do have some more goodies coming. |
|
| Back to top |
|
|
|
|
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot vote in polls in this forum
|
Powered by phpBB © 2001, 2005 phpBB Group
|